Margin of Safety #15 – Klarna – What Happened?
Jimmy Park, Kathryn Shih
May 27, 2025
- Blog Post
Klarna rolls back AI and brings back humans. Why?
Klarna’s pivot from full automation to AI augmentation shows just how hard it is to generalize early automation wins into fully automate, human-out-of-the-loop success. There’s many potential reasons for this, but we believe a large one is that early successes can often happen in simple, common tasks while full automation implies AI takeover of infrequent or high complexity tasks. This shift implies changes to both automation ROI and also technical delivery; businesses that fail to plan for such changes in advance will be forced to recon with them as they arise. Using Klarna as a example, we’ll dive into potential examples and how they might have led to this pivot.
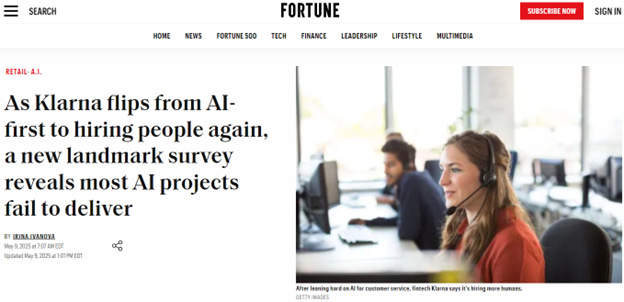
Looking at a timeline of Klarna’s announcements:
- Feb 27, 2024: Klarna announces that its AI agent is handling 2/3 of customer calls and doing the work of 700 agents (source)
- May 28, 2024: Klarna announces that AI is enabling a $10M reduction to marketing agency spend (source)
- Dec 12, 2024: Klarna CEO Sebastian Siemiatkowski tells Bloomberg TV that Klarna stopped hiring 1 year previously, due to AI’s ability to fully replace workers (source)
- May 9, 2025: Klarna tells CX dive it’s switching to a strategy in which AI augments rather than replaces human works (source)
How did this happen and what does that mean?
AI performance can be unevenly distributed
A key observation about customer support requests is that they likely represent a diverse mix of individual, specific request types. You can imagine customers asking about topics ranging from payment issues to refunds to delivery questions to fraud issues. Some of these are likely common and simple (eg, someone wants to make a return) and some are likely uncommon and potentially complex (eg, someone alleges they are a victim of identity theft). This is a classic example of what you might know as a power law, long tail, or 80/20 distribution, in which a low number of request types (~20%) represent most volume (80%). In reality, exact fractional breakdowns can vary significantly, but the important is that there are widely disparate frequencies between types.
Tuning AI systems is easiest with high data volumes – not only do these volumes give you many examples of what should be happening, but they also give you a rich, default test set to ensure that your AI capabilities are working as intended. But for complex, long tail requests, volume may be hard to come by. This often results in circumstances where it’s easy to achieve high quality for common behaviors, but it’s increasingly challenging to improve performance on the long tail. As a result, users that expect overall linear performance increases can be disappointed. A more realistic set of expectations could be something like:
· Improvements occur per request type, not for the overall function of “handle customer support requests.”
· Improvement velocity to be proportional to the learnings for that request type. For long tail types, this means either very slowly gathering more data as the requests trickle in or investing in alternate approaches such as synthetic data to accelerate learnings. However, synthetic data is both expensive and tricky to generate for complex tasks or topics. And the old saying of “garbage in, garbage out” very much applies.
If you apply these assumptions to a diverse task type with power law frequency, overall performance over time can look something like this:
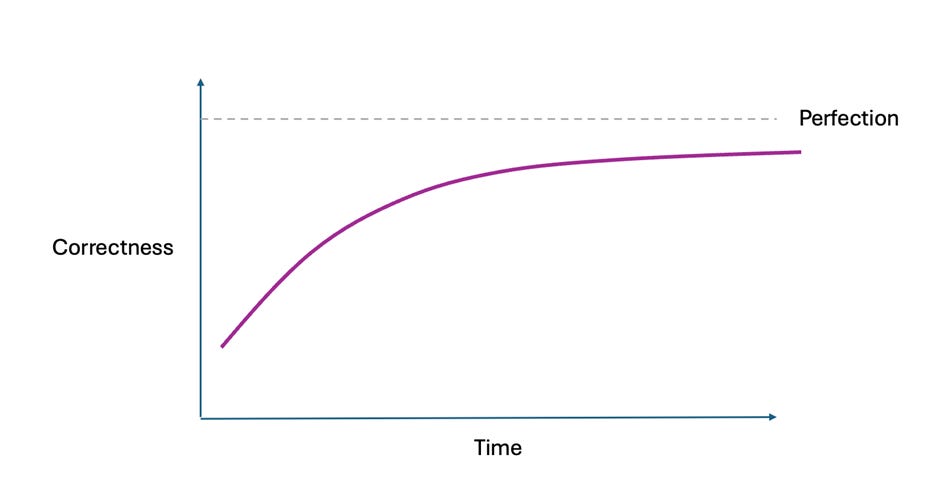
Quite frustrating compared to a baseline expectation of linear improvement! But also deeply consistent with Klarna’s early reports of substantial automation coupled with a failure, one year later, to abandon plans for full automation.
How to improve handling of long tail request
One approach is to purchase or generate synthetic data to augment training for low-volume scenarios. Synthetic data providers like Scale AI (and its increasingly many competitors) offer services where humans create thousands of examples that simulate successful task completion, which can then be used to fine-tune models. These examples don’t come cheap and reaching critical mass for improvement can easily require 100s or 1000s of examples per task type. It’s also highly dependent on your ability to source appropriate experts. For default customer support requests, that can be easy. But what if you need to improve edge case handling of complex financial requests impacted by specific jurisdictional laws? Well, now you’re looking for a very specific sort of expertise that may not even exist outside of your own staff or highly specialized firms. The capability may not be for sale in any commodity marketplace.
Another technique is to implement custom “helper” methods—deterministic subroutines that the model can call when it’s unsure how to proceed. These might include API integrations for fraud detection, rules engines for edge-case compliance issues, or retrieval-augmented systems that pull in relevant information just-in-time. While effective, these helpers introduce engineering overhead and shift the complexity from the model itself to engineering build and maintained tools. Each one becomes a miniature product requiring upkeep, governance, and its own monitoring infrastructure. Beyond technical costs, this only works when an issue can be reduces to deterministic methods. Some things – for example, determine the level of empathy and rule-bending to deliver to an upset but expensive customer – can be notoriously difficult to quantify in such a manner.
Finally, some teams are investing in intelligent routing systems that determine whether a request can be confidently handled by a lightweight model, or whether it should be escalated to a more powerful (and expensive) model—or even a human. This allows organizations to reserve compute-intensive inference for the most difficult or ambiguous cases, improving cost efficiency overall. However, this solution also introduces its own latency, operational complexity, and challenge in tuning thresholds for escalation. Plus, it’s difficult to maintain in the face of ever improving foundational model capabilities.
Collectively, these strategies represent a significant increase in both fixed and variable costs. But they’re also necessary investments if you want to expand beyond the low-hanging fruit and deliver reliable performance across the full spectrum of customer requests. The question then becomes whether they’re worth it. Look at through the lens of fixed cost increases, there may be some task types where human labor starts to look appealing versus the technical costs of automation.
So what does this mean for startups?
Klarna’s trajectory—from trumpeting full automation to settling on human-AI collaboration—offers a cautionary tale. It’s not an outlier but a preview of what many enterprises are likely to experience. As initial excitement about AI-driven automation gives way to the gritty realities of edge-case handling, we may see a wave of disillusionment ripple through the market. Startups that pitched themselves as “AI-native” may suddenly look more like traditional SaaS companies—only priced at a AI valuations.
To navigate this shift, startups will need to move away from broad, overpromised claims of full workflow automation and instead focus on narrower, higher-confidence use cases. Rather than trying to “solve customer support,” for example, a more sustainable approach might be to target specific categories like “shipping inquiries” or “returns processing.” Narrow scoping reduces long-tail complexity, improves data uniformity, and makes it easier to achieve high resolution rates and meaningful ROI in shorter timeframes. It also provides clear expansion capabilities. Over time, providers who are able to pool usage data and feedback across customers will start to have the data to break into longer tail requests and deliver greater customer value.
This changing dynamic also elevates the importance of companies focused on continuous validation and QA. As models become more integrated into critical workflows, the need to monitor, test, and retrain them continuously becomes a core enterprise requirement. Tools that detect hallucinations, monitor drift, validate grounding, and translate model behavior into dashboard metrics that non-technical stakeholders can understand will become indispensable. In many cases, these tools will resemble the picks-and-shovels businesses of the DevOps and DevSecOps eras.
Conclusion
Klarna’s journey—from bold proclamations of AI-driven workforce replacement to a humbler stance on augmentation—offers a vivid reminder that the road from demo to deployment is paved with long-tail edge cases and operational complexity. For startups, it’s a wake-up call to move beyond sweeping automation claims and instead build narrowly, validate continuously, and design for messy realities from day one. If you are building in this space, feel free to reach out!
Stay tuned for more insights on securing agentic systems. If you’re a startup building in this space, we would love to meet you. You can reach us directly at: kshih@forgepointcap.com and jpark@forgepointcap.com.
This blog is also published on Margin of Safety, Jimmy and Kathryn’s Substack, as they research the practical sides of security + AI so you don’t have to.