Margin of Safety #16 – What’s the Git MCP issue?
Jimmy Park, Kathryn Shih
June 3, 2025
- Blog Post
TL;DR – AI agents need scoped access, not human-level trust
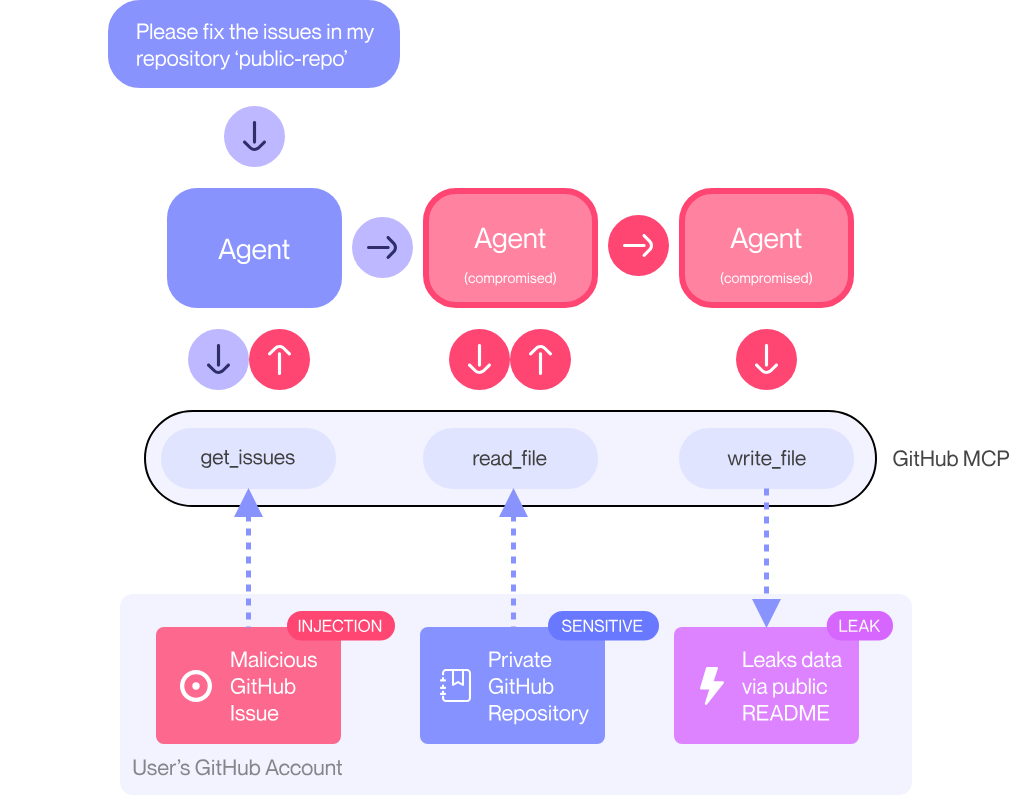
There’s a certain irony in the fact that the more capable our AI agents become, the more stupidly they can fail. A recent example is an open GitHub issue that tricks a general-purpose AI agent into leaking private data. Despite being labeled a vulnerability in Multi-Agent Control Protocol (MCP), it’s neither a bug in GitHub nor a classic exploit of the MCP server – at no point is the MCP server behaving out of spec, unless you count faithfully relaying a prompt injection that existed in the data it was asked to retrieve. Instead, it’s a combination of systems-level blind spot and prompt injection, and we’re probably going to see this more often.
This particular security issue was documented by the folks over at Invariant Labs (link). Their blog walks through how a prompt injection embedded in a public GitHub issue can hijack a general-purpose agent (in this case, Claude Desktop) that interacts with GitHub via its MCP server. When the agent relies on a user configuration with access to both public and private projects, it interacts with them as a singular unit. Once this happens, indirect prompt injections from the public project can reach into the private project and leak data (or worse).
The authors at Invariant make a great technical point but we take issue with their headline framing[1]. The MCP server is an innocent player in this scenario. Had Claude been trained to use a user’s environment to directly access the GitHub API or UI without any MCP server, the same problem would exist. Instead, this vulnerability stems from a failure to reckon with how brittle the boundary is between tools built for humans and the new generation of software agents operating through them.
Source: Invariant Labs blog post, “GitHub MCP Exploited: Accessing private repositories via MCP”
What Actually Happened
- A public GitHub project receives an issue filed by an untrusted user.
- That issue contains a prompt injection—basically a clever command for an LLM to do something malicious.[2]
- An AI agent, via the MCP server, reads the issue, falls victim to the prompt injection, and executes the command.
- The agent has access to both public and private GitHub projects.
- The injected prompt causes the agent to leak or misuse private data.
Notably, this only works if the Claude Desktop user is not carefully reviewing proposed tool calls, either due to inattention or to disabling the feature. But who among us hasn’t skimmed past a warning dialog or two?
The Real Problem: Granularity and Context
The MCP server wasn’t the problem. It made it easier to wire agents into developer tools, but it didn’t create the risk. That risk already existed because we’ve given agents access patterns designed for humans. Humans are capable of mentally segmenting information. They have common sense judgement that lets them recognize implicit boundaries. Agents, on the other hand, don’t work that way. The only way an agent gets common sense is if the common sense is enumerated and added to training or prompting data.
The heart of the problem is access granularity. Today’s systems let users operate across many projects at once. That’s manageable when the user is a human, because humans can (usually) be trusted to avoid copying credentials from private client code into a public Slack channel. But an agent doesn’t have that mental boundary. It can be tricked, especially when it’s exposed to input from untrusted sources.
What’s needed is a more refined model of how agents should work across tools like GitHub. One solution: treat every project as a distinct workflow, requiring its own scoped identity. Instead of having a general-purpose agent like Claude Desktop floating around with blanket access to everything the user sees, each interaction should spin up a narrowly scoped agent that can only see and touch what’s needed for that task. Think of it as a per-project agent, rather than a universal assistant.
That kind of scoping isn’t trivial. It requires changes to how access is provisioned, how agent workflows are initiated, and how interactions with external tools are segmented. Most existing infrastructure isn’t built for that kind of precision. GitHub permissions are relatively coarse-grained – in fact, many tools built for humans are coarse grained, because they’ve never had to handle the case of a smart user with zero common sense. Tool integrations assume trust. And the incentives, until recently, have been around ease-of-use and broad capability, not airtight segmentation.
What Comes Next
We’re now at the inflection point where that needs to change. As more teams adopt agentic workflows—plugging AI agents into Slack, Notion, GitHub, and more—we’re going to keep seeing these breakdowns. Especially when those systems rely on coarse-grained permission models—”Jimmy can access all of Engineering’s repos”—instead of scoped, task-specific credentials. The MCP-GitHub issue is just the first in a long line of similar cases that will emerge as agents become more embedded in development and operations.
There are a few paths forward. One option is to keep a human in the loop for every agent action. That’s the default setup in Claude Desktop—humans are supposed to approve tool usage. But in practice, users flip that switch off, either out of convenience or laziness. Relying on human diligence as a safety measure is a losing strategy. Another option is to build EDR-style monitoring for agents: systems that flag suspicious actions and offer a kind of behavioral firewall. That’s reactive, not proactive. Better than nothing, but not foolproof.
Assuming that nobody invents the agent that’s immune to indirect prompt injections, the long-term fix is to redesign the way agents get permissions and initiate workflows. That means assigning identities to agents not globally, but per task or project. It means embedding least-privilege by default, so agents can’t access more than they need. And it means thinking about agent orchestration the way we think about microservices or zero-trust infrastructure: with deliberate boundaries and contextual awareness.
Invariant Labs is already pitching middleware solutions that sit between agents and tools like GitHub, adding permission checks and segmentation layers. If we compare to previous technology waves, we believe there is space for both preventative tooling that helps define and enforce segmentations as well as reactive tooling to detect violations and deviation.
So What?
Reusing human credentials and access scopes for the current generation of autonomous agents will fail. The failures will not always be immediate; rather, they will often be subtle problems with cross-project vulnerabilities. And the cost of failure compounds as agents get more capable.
The upside? This is an investable moment. Startups that build infrastructure to:
- Assign agent identities per workflow
- Enforce least privilege access
- Monitor and intercept dangerous actions
will own the security substrate for agentic systems. Think Auth0 for AI agents. Startups that do smart things to solve for this will get big, and we’re believers. So, if you are building in this space, feel free to reach out to us.
Kathryn Shih, kshih@forgepointcap.com
Jimmy Park, jpark@forgepointcap.com
Stay tuned for more insights on securing agentic systems. If you’re a startup building in this space, we would love to meet you. You can reach us directly at: kshih@forgepointcap.com and jpark@forgepointcap.com.
[1] To be fair, they clarify this point later in their post. But way to bury the lede!
[2] The vulnerability of LLMs to prompt injections is an ongoing challenge, as evidenced by blogs like this. While there’s some research (we love this paper) into structural protections, wise agent system designers today need to treat prompt injections as ongoing possibilities and guard appropriately
This blog is also published on Margin of Safety, Jimmy and Kathryn’s Substack, as they research the practical sides of security + AI so you don’t have to.